








Building A1 DDP - Dubai Silicon Oasis
Industrial Area - 342001 -
Dubai - United Arab Emirates
+971 50 756 2346


SERVICES

COMPANY LINKS
SIGN-UP
For Newsletter





Computer vision is artificial intelligence that enables machines to understand images and video, identify objects, and trigger actions in real time.
The easy answer to what is computer vision? It helps software “see” visual data and use it for decisions, from medical scans and retail shelves to factory quality checks and autonomous driving.
In this guide, you’ll learn exactly how computer vision works, where it delivers business value, how it differs from machine vision and image processing, and what tools and architecture choices matter if you want production-ready results.
Make Your Next Million with Computer Vision Solution Development.
Computer vision is a branch of artificial intelligence (AI) that enables computers to process and understand visual information from the world around them.
Just like humans use their eyes and brain to recognize and react to what they see, computer vision allows machines to do the same, automatically identifying objects, scenes, people, and actions in digital images and videos.
Did you know?
The global computer vision market reached $19.8 billion in 2024 and is projected to surpass $58 billion by 2030. (1)
The main goal of computer vision is to enable machines to see, understand, and act on visual information the way humans do (using images and video to make accurate, real-world decisions).
In practical terms, computer vision aims to:
In short, computer vision exists to transform visual input into reliable, machine-driven understanding and action at scale.
Computer vision is used in many industries to solve real problems, speed up processes, and reduce human error. Here are some of the top Vision AI use cases:
1. Retail & Inventory Management
2. Automotive & Transportation
3. Healthcare
4. Security Systems
5. Everyday Devices
Did you know?
Computer vision adoption is accelerating: 42% of enterprises have already implemented AI solutions, while another 40% are actively exploring them, according to IBM. (2)
Computer vision works by teaching computers how to interpret and make decisions from visual input, images, or video, using artificial intelligence and mathematical models. Here's a simplified breakdown of the typical process:
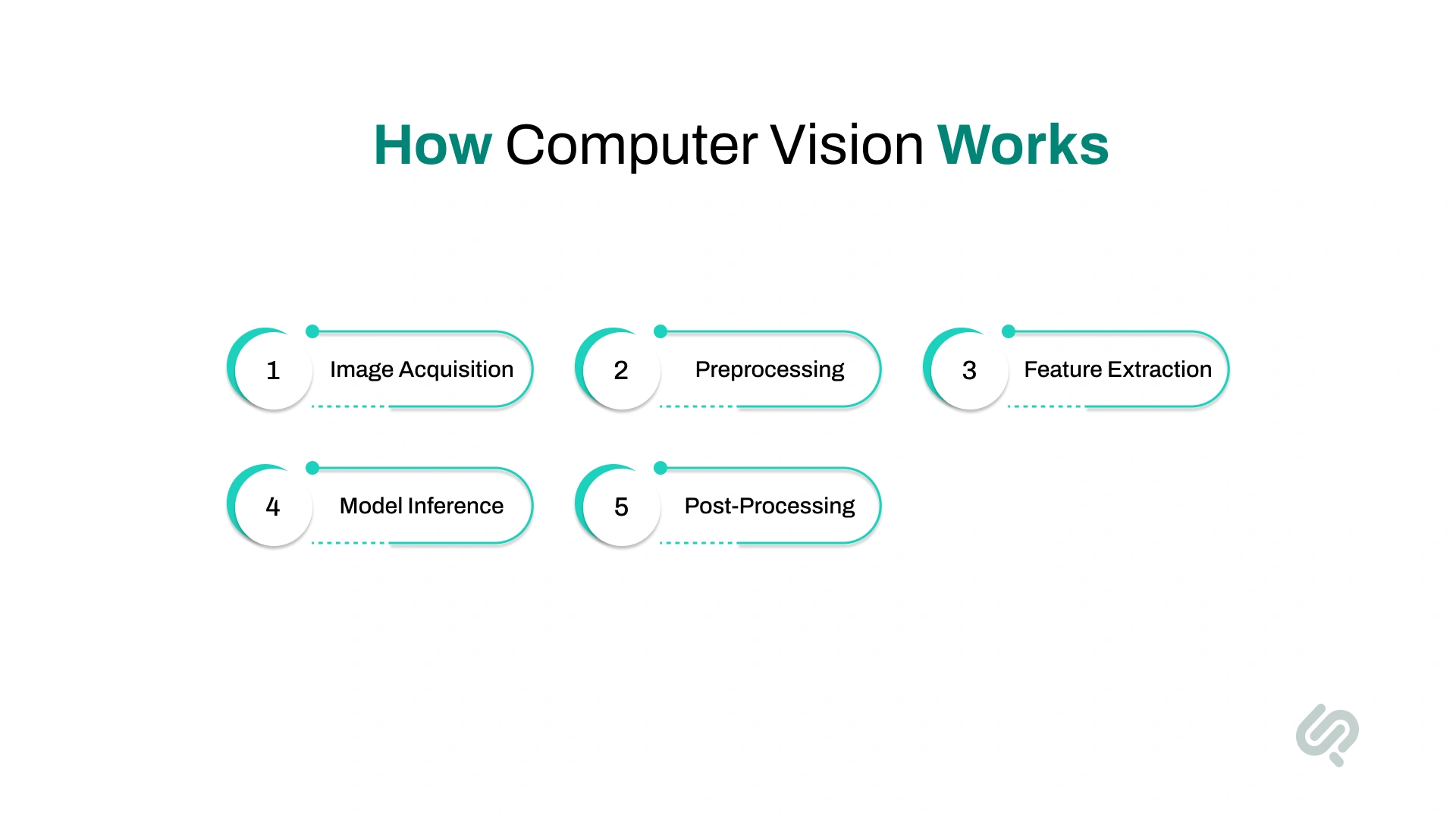
The system captures input from a digital camera, video feed, or sensor. This is the input image used for processing.
Images are cleaned and standardized, resized, de-noised, or enhanced for better clarity. This ensures consistent results regardless of lighting or angle.
The system identifies important parts of the image, such as edges, corners, textures, or patterns. These features help it distinguish between different objects or scenes.
Deep learning models (like CNNs, Vision Transformers, or GANs) analyze the features and classify, detect, or segment objects in the image.
The system outputs its prediction (e.g., “stop sign detected”) and triggers a response, like slowing down a self-driving car or flagging a quality issue on an assembly line.
Computer vision systems can be deployed in different environments depending on performance, privacy, and infrastructure needs. The right deployment model impacts speed, cost, and compliance.
Best for scalability and fast setup.
Best for real-time and low-latency use cases.
Best for strict data control and compliance.
These three terms are often used interchangeably, but they solve different problems and require different levels of intelligence.
In simple terms:
Here’s a quick comparison:
This distinction helps teams choose the right approach when deciding how to build or buy visual AI systems.
Computer vision systems perform a set of core tasks that allow machines to “see,” understand, and act on images and video. These tasks are the building blocks behind real-world applications like self-driving cars, medical imaging, facial recognition, and smart retail.
Below are the most important computer vision tasks you should know:
What it does: Finds and labels objects in an image or video.
Why it matters: Enables systems to locate people, vehicles, products, or hazards in real time.
Common uses:
What it does: Splits an image into meaningful regions by labeling each pixel.
Why it matters: Helps systems understand scenes in detail, not just object location.
Common uses:
What it does: Reads text from images and scanned documents.
Why it matters: Converts visual text into searchable, usable data.
Common uses:
What it does: Assigns a label to an entire image based on what’s inside it.
Why it matters: Enables fast categorization of visual content.
Common uses:
What it does: Follows the same object across multiple video frames.
Why it matters: Supports motion analysis and real-time monitoring.
Common uses:
What it does: Detects body joints or object positions in 2D or 3D space.
Why it matters: Enables motion understanding and gesture-based interaction.
Common uses:
What it does: Identifies or verifies people based on facial features.
Why it matters: Enables secure access and identity verification.
Common uses:
What it does: Understands depth, distance, and spatial layout of scenes.
Why it matters: Allows machines to navigate and interact with physical environments.
Common uses:
What it does: Creates or improves images using AI models.
Why it matters: Helps improve data quality and simulate rare scenarios.
Common uses:
Computer vision helps businesses turn images and video into real-time, actionable insights. Below are the most impactful real-world applications of computer vision across industries like retail, healthcare, security, and automotive.
Computer vision helps retailers automate inventory tracking, monitor shelf activity, and improve in-store experiences.
Computer vision enables self-driving systems to “see” and understand road environments using cameras and sensors.
AI-powered vision systems monitor spaces for threats and unauthorized access without constant human oversight.
Computer vision supports faster and more accurate analysis of medical scans.
Vision systems inspect products and assemblies on production lines to reduce defects and waste.
Computer vision allows AR/VR systems to understand physical spaces and align digital content with the real world.
Computer vision is expanding into new domains beyond traditional industries.
Computer vision systems are powered by a combination of artificial intelligence, deep learning models, and data processing techniques that enable machines to interpret visual information and make decisions.
These technologies work together to help computers recognize patterns, understand scenes, and act on visual data in real-world environments.
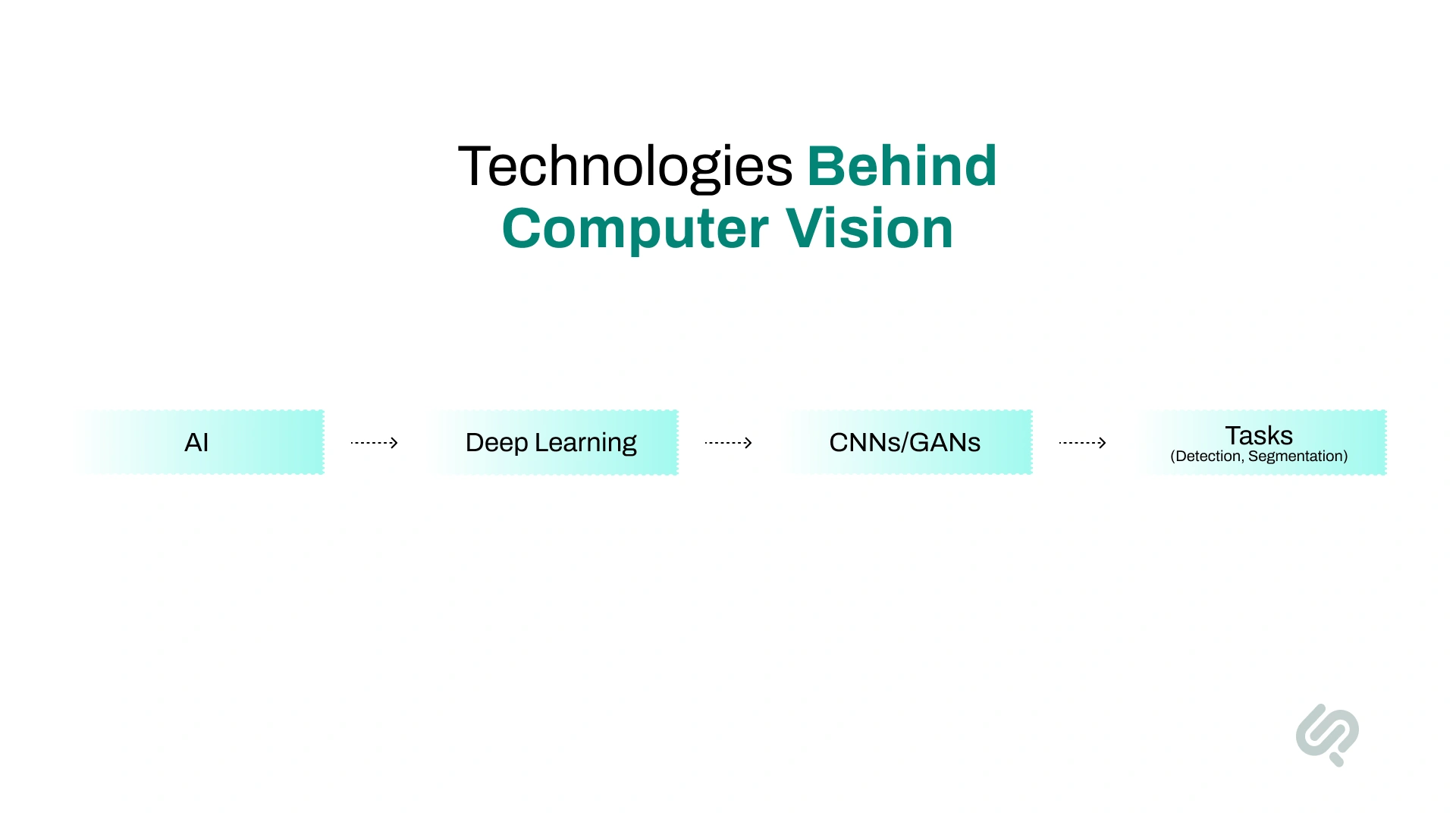
Computer vision is a subfield of AI that enables machines to interpret images and video. Machine learning allows systems to improve performance over time by learning from labeled visual data.
Deep learning enables models to automatically learn visual features from raw images without manual programming.
CNNs are the backbone of most computer vision systems, designed specifically for image analysis.
GANs generate realistic images by training two competing models.
This process identifies important visual patterns such as corners, edges, and textures.
ViTs apply transformer architectures to visual data.
Visual data must be cleaned and standardized before training.
Multimodal systems combine vision with text, audio, or sensor data.
Businesses across industries are adopting computer vision technologies to streamline operations, improve safety, and unlock new value from visual data.
About 42% of enterprise-scale companies report actively using AI in their business, while another 40% are exploring or experimenting with it, indicating strong momentum toward broader deployment. (3)
From healthcare to agriculture and manufacturing, these real-world applications show how powerful computer vision solutions are in practice:

Companies use computer vision systems to inspect products and identify defects on production lines—faster and more accurately than manual inspection.
Computer vision in healthcare assists doctors by analyzing X-rays, MRIs, and CT scans to detect early signs of illness.
Computer vision for autonomous driving helps self-driving cars safely interpret and respond to road environments.
In farming, computer vision technology monitors crop health and optimizes field management.
Retailers and marketers use computer vision to analyze visual content across platforms, including social media.
Facial recognition systems powered by computer vision help secure workplaces, events, and public areas.
Computer vision models can detect signs of wear or failure in equipment before problems happen.

Leading tech companies offer robust platforms for building and deploying computer vision solutions.
When building a computer vision solution, one of the first decisions is whether to use a prebuilt computer vision API or develop a custom computer vision model. The right choice depends on your use case, data, accuracy needs, and how critical vision is to your product or operations.
Examples: AWS Rekognition, Google Vision API, Azure Computer Vision
Hybrid approach (often the best path):
Many teams start with an API to prove value, then transition to a custom model once the use case, data, and ROI are clear. This reduces risk while still allowing long-term scalability and control.
Some challenges to watch out for are:
1. Data Bias and Fairness
Vision models can inherit bias from unbalanced or non-diverse image datasets. This can lead to errors in facial recognition, healthcare diagnoses, and security systems.
2. Interpretability and Trust
Deep learning models like CNNs or generative adversarial networks often act as black boxes. It’s hard to explain why they made a decision.
3. Data Privacy & Security
Vision systems deal with sensitive data—like faces, license plates, or medical records. Ensuring privacy is essential.
4. Generalization Across Environment
Many computer vision models struggle when used in different settings, like lighting changes, weather conditions, or camera angles.
More companies are moving vision models from the cloud to edge devices like smartphones, drones, and IoT cameras. This reduces latency and improves real-time performance.
Future systems will better understand depth, space, and 3D structure—crucial for robotics, AR/VR, and autonomous navigation.
Multimodal AI, combining vision with language, audio, or sensor data, is reshaping how systems understand context.
At Phaedra Solutions, we’re seeing computer vision shift from “object detection demos” to context-aware decision systems that run in real operations, warehouses, hospitals, and field environments.
The biggest change is not just better model accuracy. It’s better business accuracy: lower false alerts, faster response times, and measurable outcomes teams can trust.
As Hammad Maqbool, AI Expert at Phaedra Solutions, puts it:
“Computer vision delivers real value when it moves beyond detecting objects and starts understanding operational context. The goal isn’t just model accuracy. It’s dependable decisions teams can trust in live environments.”
Our teams are also seeing strong momentum in three areas:
Computer vision is no longer just a research topic. It’s a real-world technology driving innovation across industries.
Whether it’s powering self-driving cars, helping doctors analyze medical images, or allowing retailers to track inventory in real time, computer vision is unlocking new ways to process and understand the visual world.
As more businesses adopt computer vision solutions and invest in AI consulting, the demand for smarter, faster, and more ethical systems will continue to rise.
If you’re looking to build or scale your own vision AI project, now’s the time to explore the tools, techniques, and expert guidance that can bring it to life.
Book a Free 30-minute Computer Vision AI Consulting Session.


Ameena is a content writer with a background in International Relations, blending academic insight with SEO-driven writing experience. She has written extensively in the academic space and contributed blog content for various platforms.
Her interests lie in human rights, conflict resolution, and emerging technologies in global policy. Outside of work, she enjoys reading fiction, exploring AI as a hobby, and learning how digital systems shape society.
